The VERA:H framework
7-minute read. Five elements built into every prompt before AI drafts. Pen out, or notebook open.
You met Edgar and Delroy in Section 1. You saw why their AI-drafted paragraphs differed in Section 2. Now we give you the framework that closes the gap. VERA:H. Five elements you build into every prompt, before you ever ask AI to draft an assessment paragraph for you.
This is the practical section. By the end you will have a reusable habit, not an idea.
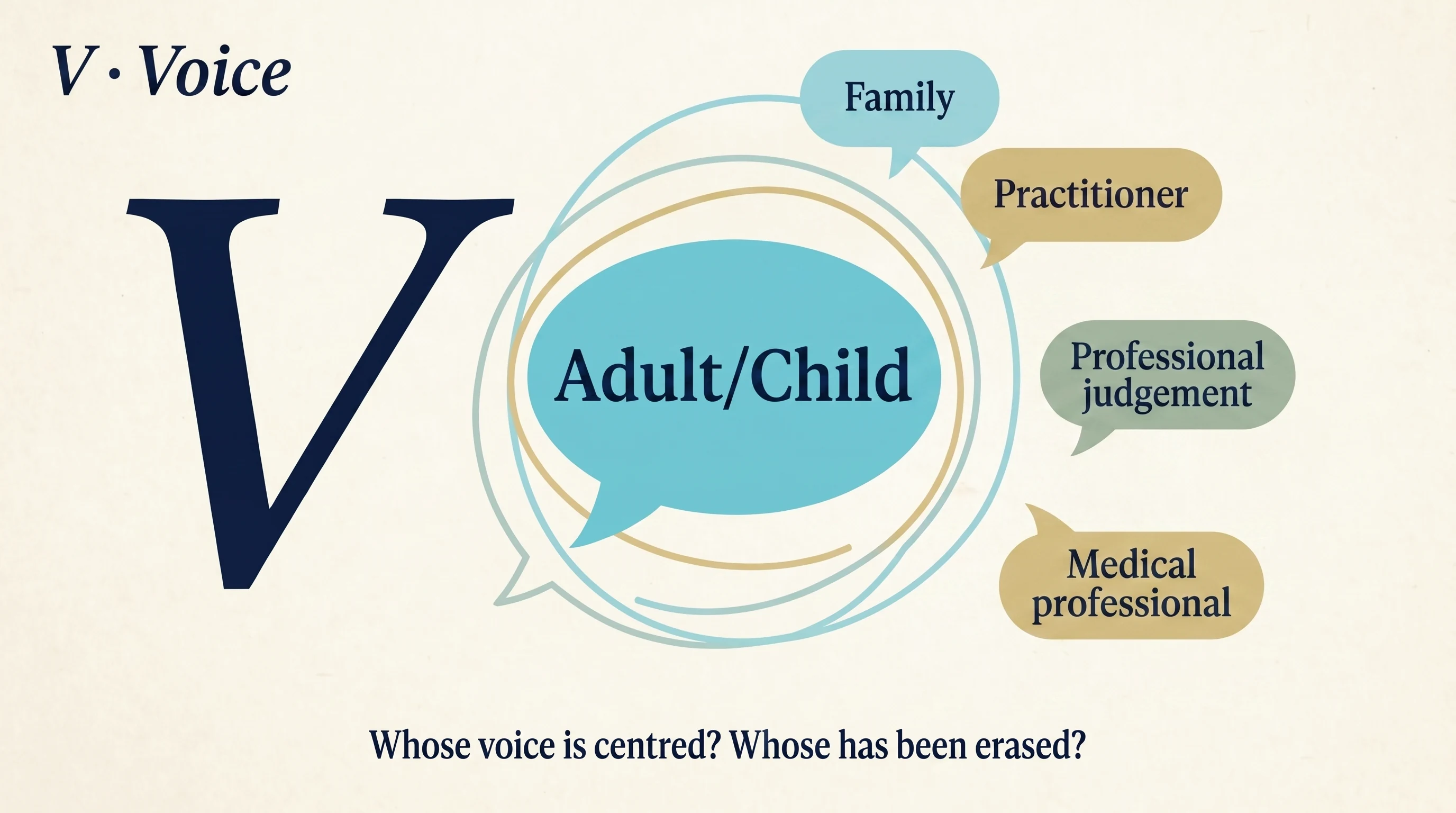
Every record in social work carries multiple voices. The service user's voice. The family's voice. The practitioner's professional judgement. The voices of medical professionals, advocates, school staff, youth workers, support workers, friends, neighbours. Professional judgement is itself a voice, one of the most consequential ones.
These voices do not always agree. The medical model and the social model can sit in real tension in a single case. A parent may want one thing while their child wants another. A consultant may frame a person's life through the lens of diagnosis while the person frames it through the lens of relationship.
The job is not to flatten these tensions. The job is to make them visible, accurately, with the service user's voice held at the centre and not drowned out. Where the service user's voice is mediated through an advocate, that should be visible. Where the voice of the child differs from what the parent wants, that difference must be documented clearly, not edited into a polite consensus that never existed.
When you brief AI, name the voices. "This assessment must include the service user's words verbatim where given. Family input is contextual. Medical opinion is one voice among several, not the conclusion." That instruction alone changes what AI returns to you.

A safe assessment draws on many sources, not one. The systems around a person: schools, youth workers, personal tutors, LD nurses, GPs, family, grandparents, parental guardians, neighbours, colleagues. Every one of them is a potential source of evidence.
Over-relying on a single source is a known failure mode in serious case reviews. Relying only on what the parent says, or only on what the school says, produces a partial picture that AI will then draft into a confident-sounding paragraph.
When you brief AI with evidence, be very clear where each piece came from. Tag the source. "Mrs Begum (mother) reports X. The class teacher (Ms Walsh, observed 14 March) reports Y. The child themselves said Z when asked directly." Without source-tagged evidence, AI will smooth attribution into a single voice, and you cannot tell when you read the output back which line came from where.
Voice and evidence are paired. The voice tells you whose perspective. The evidence tells you the source and weight. Both must be in the prompt before AI starts drafting.

Why are you doing this piece of work?
A children's assessment, an adult safeguarding referral, a Care Act assessment, a Mental Capacity Act assessment, a supervision record, a case note, a court report. Each is a different kind of document with different statutory expectations, different audiences, and different conventions of voice. AI does not know which one you are writing unless you tell it.
This is the reasoning step: the purpose of the document. "I am drafting a Care Act assessment opening. The audience is the panel. The legal frame is the Care Act 2014. This is the practitioner's voice, supported by evidence, contributing to the eligibility decision."
Without this context, AI will fall back on its statistical defaults: usually a generic clinical-bureaucratic register that suits no specific document type and may misframe the work. With this context, AI shapes the draft to fit. The reasoning is not the conclusion. The reasoning is what kind of document this is and why it exists.
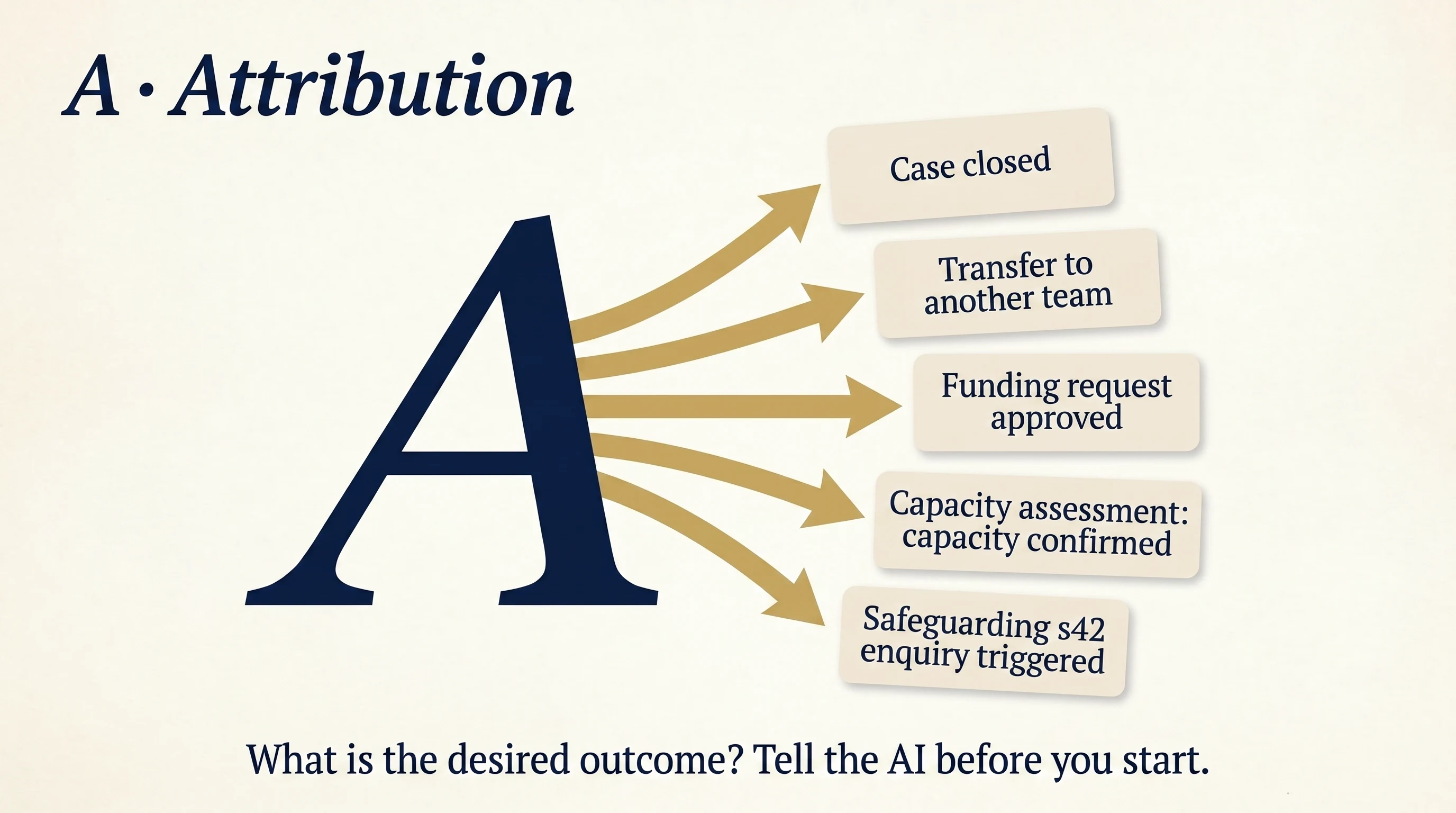
Reasoning is the purpose of the document. Attribution is the outcome you are working towards. They are not the same thing.
For a safeguarding s42 enquiry: the attribution is what should happen next: triggering an enquiry, closing without action, referring on to police, convening a strategy meeting. For a Mental Capacity Act assessment: capacity confirmed, or capacity not confirmed, with respect to which specific decision. For a Care Act review: case closure, package change, transfer to another team, funding request approved.
When you tell AI the attribution before it drafts, it builds a paragraph that supports the proposed outcome with the right voices and the right evidence in the right place. Without it, AI may draft an opening that conflicts with the conclusion you want to land. And under time pressure you may not catch the inconsistency before the document goes out.
The voice tells AI who. The evidence tells it from where. The reasoning tells it what kind of document. The attribution tells it where the document is going. All four feed each other.

You are the human in the loop, and not because of any quality-assurance role at the end of the process. You are the only entity who was actually there when the case happened.
The AI was not in the front room while a daughter wept about her father refusing services, or watching a child go silent when their stepfather walked in. It was not on the home visit, and it does not know the case. You do.
The H is not "human-in-the-loop" in the AI-industry sense of a quality-assurance step at the end. The H is we are the humans. We were in the room. We add the voice, give the evidence, provide the reasoning, decide the attribution. AI cannot run any of V, E, R, or A without us being part of what it does.
The more you put in at the top, with full voice, sourced evidence, clear reasoning, and named attribution, the less AI has to fill in from its statistical defaults, and the fewer hallucinations you get downstream. VERA:H is, partly, hallucination mitigation. It is also bias mitigation, drift mitigation, and confidence-trap mitigation.
VERA:H is not a stopgap. It does not solve every problem AI brings to social work practice. Mistakes will still happen. A well-structured prompt does not guarantee a safe output. Bias creeps back in at multiple points: in how the model interprets your prompt, in how it weights your sources, in how it phrases the draft you read back.
What VERA:H does do is make the most common errors less likely. Hallucinations narrow when context is rich, bias narrows when voice is named, and drift narrows when attribution is explicit. The errors stay possible. VERA:H makes them rarer and more visible when they happen.
You still read the output the way you would read a colleague's note where something feels wrong. You still push back where it feels off. You still own the document with your name on it. VERA:H is a discipline, not a solution.
The takeaway, in five lines
- V: name the voices, centre the service user's
- E: tag the evidence, never rely on one source
- R: name the kind of document and why you are writing it
- A: name the desired outcome before you start
- H: you are the human, not a checkpoint at the end
Pick a document you wrote in the last week: assessment, referral, supervision note, anything. Walk it through VERA:H in your head. Whose voice was centred? How many sources did the evidence draw from? What kind of document was it, and what was the attribution? Where was your professional judgement most consequential?